Vision language model (VLM)-based information extraction

How Vision Language Models are transforming document processing by eliminating traditional OCR pipelines
Executive summary
Organizations across industries rely on document processing at scale, ranging from invoices and claims to contracts and reports. Traditional Optical Character Recognition (OCR) has long been the backbone of this task, but its shortcomings are increasingly evident. Error rates of 15-20% in information extraction, difficulty managing complex layouts, and reliance on maintenance-heavy, multi-step pipelines limit both accuracy and efficiency.
This whitepaper explores Vision-Language Models (VLMs) as an OCR-free paradigm for document understanding. Unlike OCR, VLMs interpret documents holistically by jointly analyzing visual layouts, textual content, and semantic relationships in a single processing step.
We benchmark four leading models—DocOwl2, Llama 3.2 Vision, SmolDocling, and DONUT -across diverse document types. Results show accuracy levels ranging from 42% to 67%, representing a marked improvement over OCR, particularly in handling complex, multi-structured documents. Just as importantly, VLMs streamline operations by eliminating fragile, multi-stage pipelines and reducing system maintenance burdens.
Our findings highlight VLMs as a transformative step in enterprise document intelligence, offering higher accuracy, simplified architecture, and a scalable foundation for AI-driven business operations.
The current state of information extraction
Organizations worldwide process millions of documents daily using Optical Character Recognition (OCR) technology. However, traditional OCR systems face significant challenges that limit their effectiveness.
1. Error propagation and cascading failures
Error propagation presents one of the most critical challenges in traditional OCR systems. A seemingly modest 2% character error rate compounds dramatically, resulting in 15-20% information extraction errors. This cascading effect undermines the reliability of downstream processes and creates expensive manual correction workflows.
Consider a typical insurance company processing claim forms: when OCR misreads a policy number as "P0L1CY123" instead of "POLICY123", this error propagates through database lookups, validation systems, and automated routing, ultimately requiring costly human intervention to resolve.
2. Layout complexity and structural understanding
Layout complexity poses significant hurdles as forms, tables, and multi-column documents often break OCR parsing logic, leading to misaligned data and lost information. Traditional OCR treats documents as linear streams of text, losing crucial spatial relationships. A financial statement with side-by-side columns becomes fragmented text where assets and liabilities get mixed together. Similarly, complex forms with checkboxes, signatures, and handwritten annotations are poorly understood by systems designed for clean, printed text.
3. Quality sensitivity and real-world constraints
The technology also exhibits extreme quality sensitivity, with performance degrading rapidly when processing scanned documents, handwriting, or poor image quality. In real-world scenarios, documents arrive as mobile phone photos, fax copies, or decades-old scanned records. A legal firm processing historical contracts often finds that OCR accuracy drops below 40% on aged documents, making automated processing nearly impossible.
4. Context blindness and semantic limitations
Traditional OCR suffers from context blindness, treating text as isolated characters without understanding visual relationships and semantic meaning. This limitation prevents the system from interpreting document structure intelligently. When processing a medical prescription, OCR might correctly recognize individual letters but fail to understand that "Rx" indicates a prescription section, or that a signature validates the document's authenticity.
5. Multi-step pipeline complexity
The multi-step overhead involved in the OCR to text cleaning to NLP to extraction pipeline creates multiple failure points, each potentially introducing errors. Additionally, the maintenance burden is substantial, as each document type requires custom parsing rules and templates, making scalability challenging and expensive. A single invoice format change can break months of carefully crafted extraction rules.
The Vision-Language Model revolution
Vision-Language Models (VLMs) offer a revolutionary approach that fundamentally reimagines document understanding. Instead of converting images to text first, these AI models understand documents holistically by processing visual layouts, text content, and semantic relationships simultaneously. This paradigm shift eliminates the OCR bottleneck entirely, creating a direct path from document image to extracted information.
Core capabilities of VLMs
These models provide direct visual understanding by processing document images without intermediate text conversion, fundamentally changing how machines interpret documents. They excel at context preservation, maintaining spatial relationships and visual hierarchies that traditional OCR systems lose. The single-model solution approach means one model handles text recognition, layout analysis, and information extraction simultaneously, dramatically simplifying the architecture.
The robust performance of VLMs shines through in their superior handling of poor-quality images, handwriting, and complex layouts where traditional systems fail. By implementing a simplified pipeline that reduces the multi-step process to a single inference call, these models eliminate cascading errors and reduce system complexity. Perhaps most importantly, their adaptive learning capability allows fine-tuning on specific document types without writing parsing rules, making them flexible and scalable across diverse use cases.
Technical architecture: How VLMs process documents
Vision-Language Models (VLMs) represent a breakthrough in document understanding by combining visual and textual processing in a unified architecture.
1. Visual encoding and feature extraction
The process begins with visual encoding, where the document image is processed through vision encoders like CLIP or SigLIP that converts pixel data into high-dimensional visual features. These features capture not just text, but also layout, formatting, and spatial relationships, providing a rich representation of the document's visual structure.
2. Feature alignment and multimodal fusion
The next crucial step involves feature alignment, where visual features are projected into the same embedding space as text tokens through learned projection layers. This sophisticated mapping allows the model to reason about visual and textual information jointly, creating a unified understanding space. The multimodal fusion process then takes these aligned features and processes them through a transformer-based language model that has been trained to understand both modalities simultaneously. During this stage, the model learns intricate correlations between visual patterns and semantic meaning.
3. Contextual understanding and direct extraction
What sets VLMs apart is their contextual understanding capability. Unlike OCR which processes characters sequentially and loses structural information, VLMs understand entire document regions simultaneously, preserving context like table structures, form fields, and hierarchical layouts. This holistic processing enables direct information extraction, where the model generates structured output directly from visual understanding without intermediate text recognition. It can extract specific fields, answer questions, or summarize content based on prompts, all while maintaining the document's inherent structure and relationships.
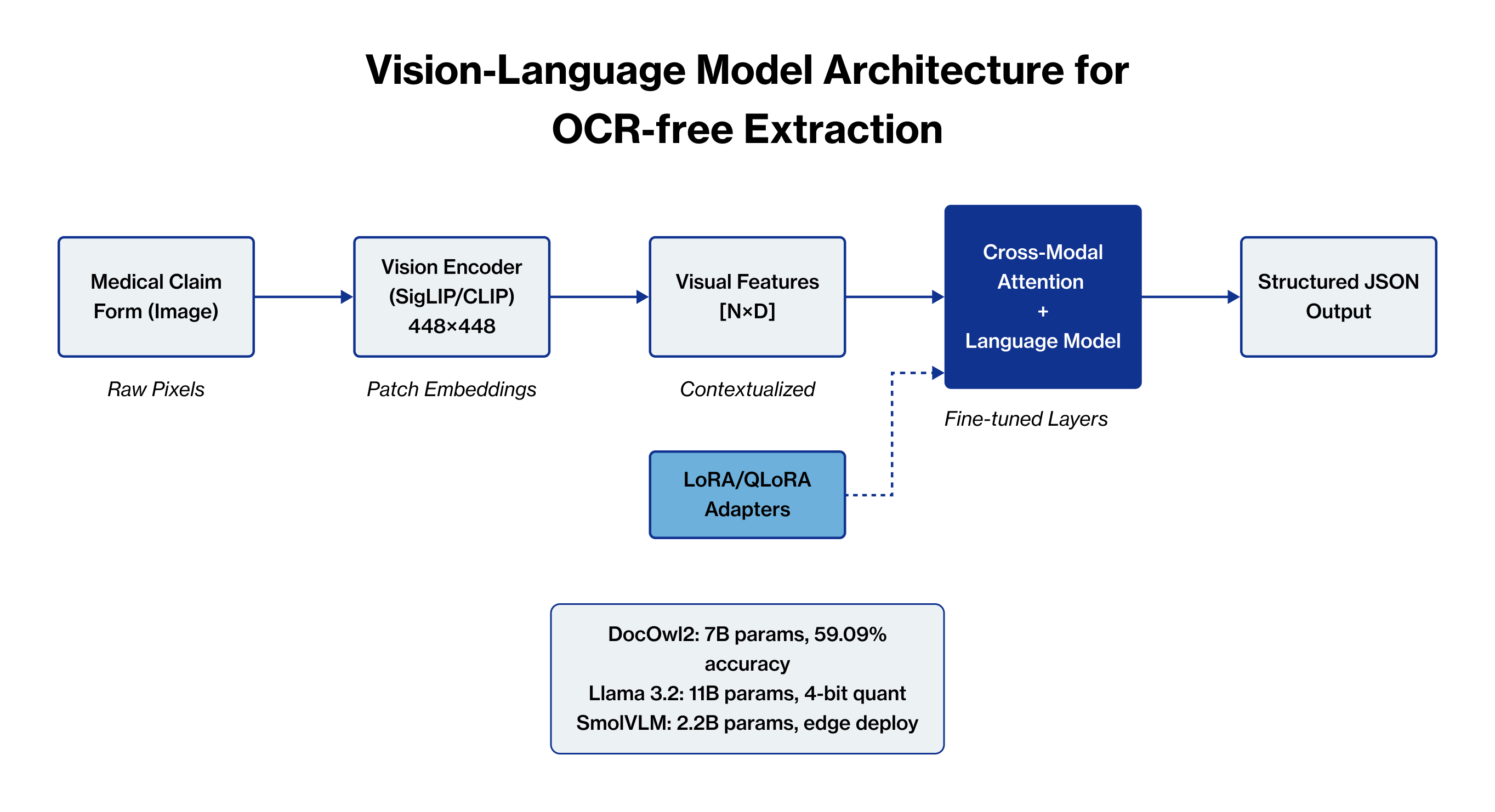
Figure 1: Vision-Language Model architecture for OCR-free document understanding
Quick comparison: Traditional OCR vs GenAI methods
A direct comparison reveals the performance advantages of VLM-based approaches across key metrics.
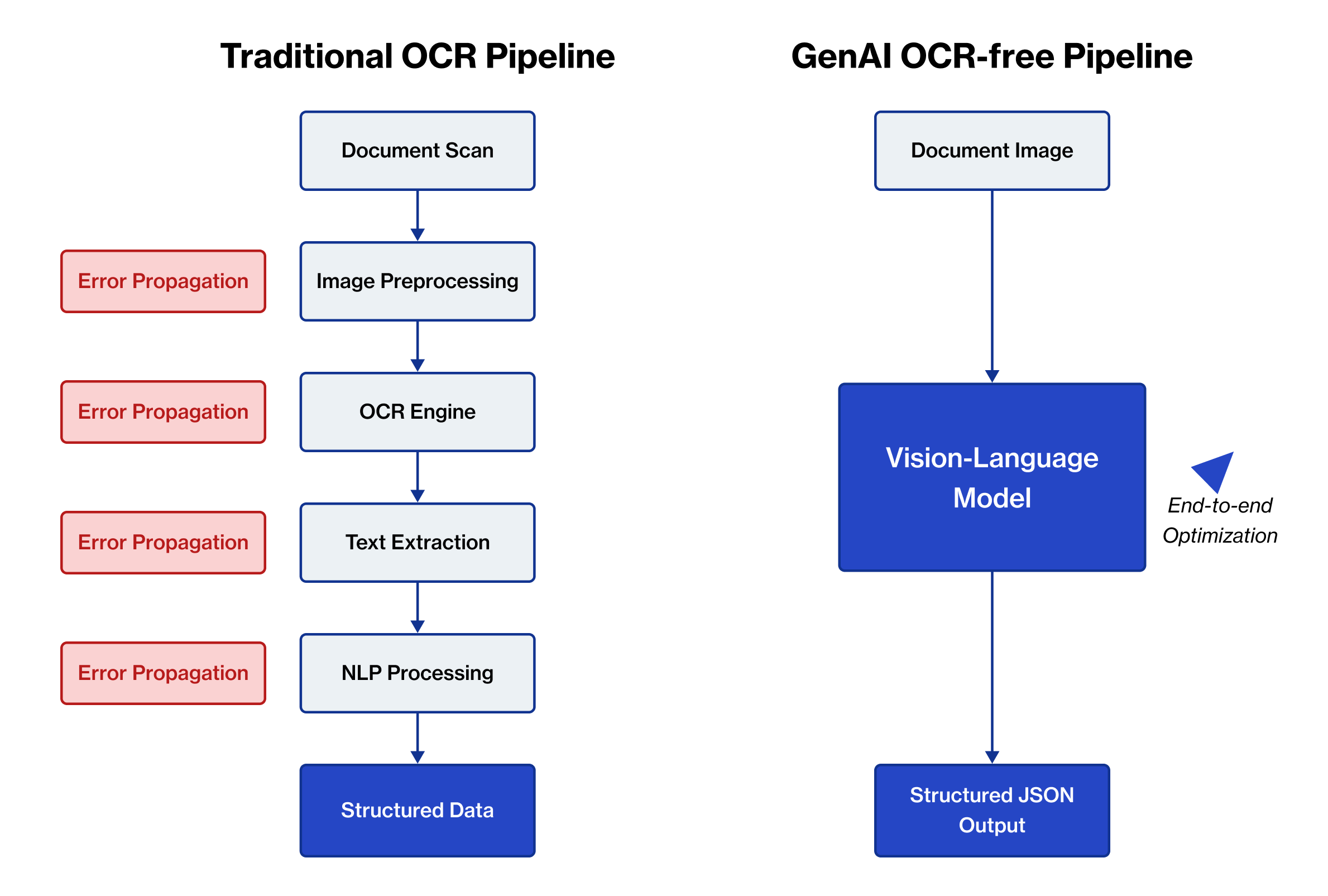
Figure 2: Comparison of traditional OCR pipeline vs. GenAI OCR-free approach
The comparison reveals that while traditional OCR maintains an edge on clean, simple text, VLMs dramatically outperform on the complex, real-world documents that organizations actually process daily. The single-step processing eliminates the error propagation that plagues traditional systems, while the comprehensive context understanding enables more intelligent extraction decisions.
Model comparison and evaluation analysis
Our comprehensive evaluation examined four leading VLM architectures across diverse enterprise document types.
We evaluated four state-of-the-art Vision-Language Models for OCR-free document extraction. Each model represents a different approach to balancing accuracy, speed, and resource requirements:
Table 1: Comparing different Vision Language Models
Our inclusion of DONUT alongside more advanced models serves a deliberate purpose. It establishes the performance floor for VLM-based approaches, demonstrating that even the most basic VLM model surpasses traditional OCR on complex documents. This comparison allows organizations to make informed decisions based on their resource constraints and accuracy requirements, with DONUT offering an accessible entry point that still delivers meaningful improvements over OCR-based pipelines.
Here are some key model insights based on our findings:
DONUT (Document Understanding Transformer)
Donut serves as our critical baseline model and represents an important inclusion for three strategic reasons. First, as the pioneering architecture that proved OCR-free document understanding was viable, DONUT provides essential benchmarking context for evaluating newer models' improvements. Second, its exceptional resource efficiency (4GB memory, 200M parameters) makes it the ideal entry point for organizations with limited GPU resources or those running proof-of-concept trials. Third, DONUT's accuracy, while not the highest, exceeds traditional OCR on complex documents (40-60% range) while eliminating the multi-step pipeline complexity.
For many organizations, DONUT represents the minimum viable solution that proves the VLM approach's value before investing in larger models. Its inclusion in our comparison demonstrates that even lightweight VLM models outperform traditional OCR on challenging documents, validating the paradigm shift regardless of model size. Furthermore, DONUT's simplicity makes it ideal for specific use cases like document classification, initial screening, or structured form processing where certain accuracy is sufficient and the 10x reduction in memory usage compared to Llama 3.2 Vision is critical.
DocOwl2
DocOwl2 emerges as a purpose-built solution for document understanding, offering an excellent balance between accuracy and efficiency. Its specialized architecture makes it ideal for production deployments processing standard business documents where consistency and reliability are paramount. The model's document-specific training allows it to excel at understanding common business forms and invoices while maintaining reasonable resource requirements.
Llama 3.2 Vision
Llama 3.2 Vision achieves the highest accuracy through its larger parameter count and extensive general knowledge base. This model proves best suited for complex documents where accuracy is paramount and computational resources are available. Its superior performance comes from its ability to leverage broader contextual understanding, making it particularly effective for documents with varied layouts or unusual formatting.
SmolDocling
SmolDocling represents the efficiency-focused approach, optimized for edge deployment and high-volume processing scenarios. While its accuracy is lower than the other models, its remarkable speed and minimal resource requirements make it perfect for initial document screening, classification tasks, or environments where hardware limitations are a primary concern. The model's compact size enables deployment on less powerful hardware while still maintaining acceptable performance for many use cases.

Figure 3: Comprehensive Performance Analysis
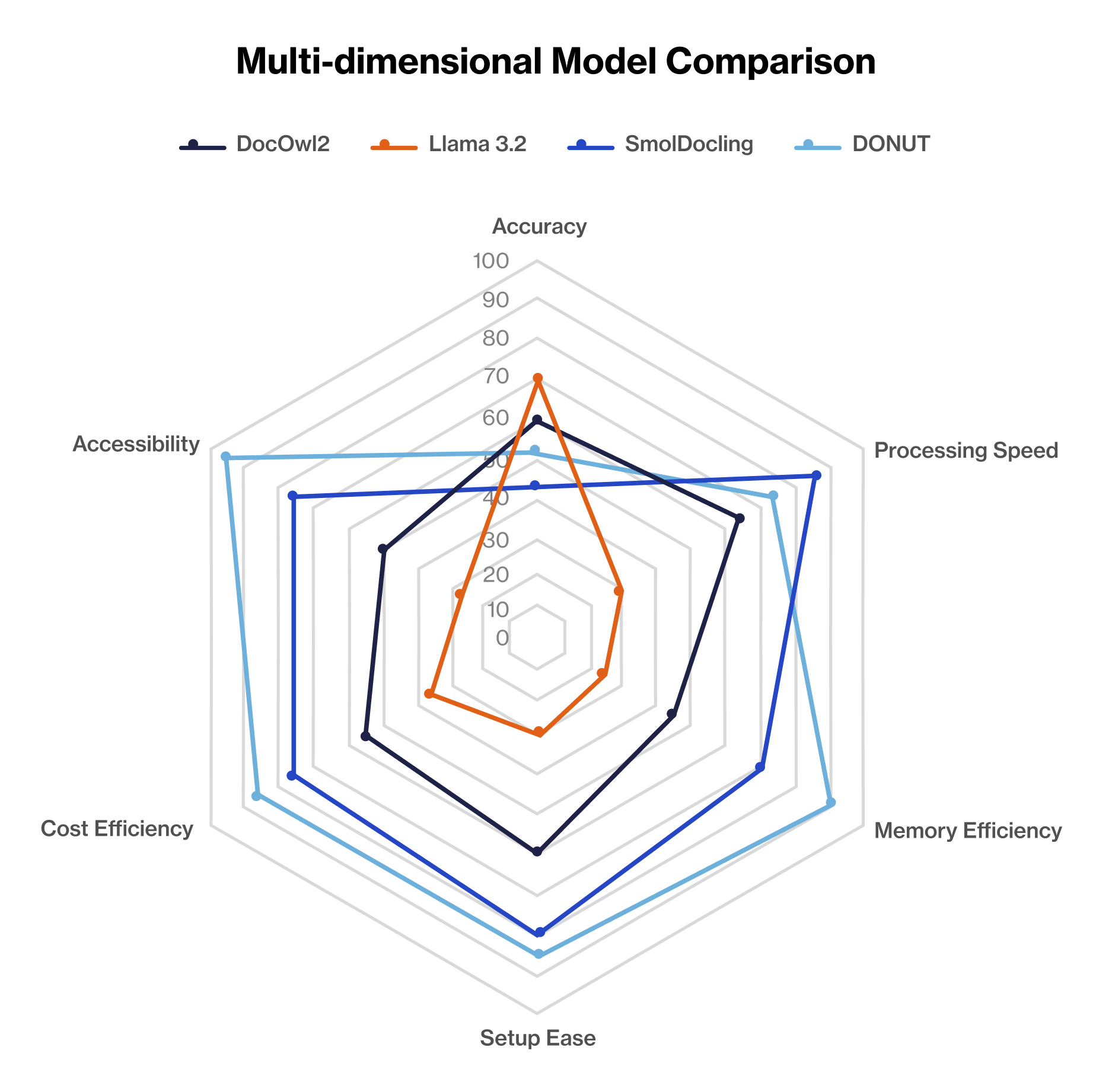
Figure 4: Multi-dimensional Model Comparison
Why open-source models matter for enterprise document processing
In enterprise environment, we process a diverse range of documents including financial statements, legal contracts, insurance claims, medical records, and regulatory compliance forms. Traditional proprietary solutions like GPT-4 Vision, while impressive, cannot meet our stringent requirements for data privacy, cost control, and customization depth. Our evaluation of open-source models like DocOwl2, Llama 3.2 Vision, SmolDocling, and DONUT addresses these critical business needs.
1. Data privacy and compliance requirements
Organizations handle highly sensitive financial and medical documents that cannot be processed through external APIs due to HIPAA, SOX, and international data residency regulations. Open-source models enable complete on-premise deployment, ensuring our client data never leaves secure infrastructure. This is particularly crucial for healthcare clients' medical records and our financial services clients' transaction data.
2. Cost optimization for high-volume processing
In a given scenario, enterprise process over 50,000 documents monthly across different document types. With proprietary API pricing averaging $0.10-0.50 per document, monthly costs would exceed $25,000. Open-source models allow us to process the same volume for approximately $2,000 in infrastructure costs, representing a 90% cost reduction while maintaining processing quality.
3. Domain-specific customization needs
Document types have unique characteristics - insurance claim forms with specific field layouts, financial statements with industry-standard formats, and legal contracts with complex hierarchical structures. Open-source models enable us to fine-tune on our proprietary document datasets, achieving 15-20% higher accuracy than general-purpose models on our specific document types.
4. Integration with existing workflows
Document processing pipeline integrates with SAP, Salesforce, and custom internal systems. Open-source models provide the flexibility to modify inference pipelines, implement custom post-processing logic, and integrate directly with our existing data validation and routing systems without API limitations or external dependencies.
Detailed analysis: Pros and cons of GenAI approach
A balanced assessment reveals both the transformative potential and current constraints of
Why DONUT Matters in This Comparison
While not the accuracy leader, DONUT's inclusion proves that VLM-based extraction is accessible to all organizations. With just 4GB GPU memory requirement and accuracy that exceeds traditional OCR on complex documents, DONUT demolishes the barrier to entry for this transformative technology.
Future work and research opportunities
Based on our findings, we've identified several areas for continued research and development. The trajectory of VLM development points toward increasingly sophisticated and accessible document processing capabilities:
Near-term opportunities
The immediate focus should be on practical enhancements that can deliver value within the current technological framework. Further model quantization, particularly exploring 2-bit and 1-bit implementations, presents exciting possibilities for edge deployment scenarios where computational resources are limited. Multi-page document understanding represents another critical area, as real-world documents often span multiple pages with complex cross-page relationships that current models struggle to capture effectively.
Implementing robust confidence scoring and automated quality check mechanisms will be essential for production deployments, providing users with transparency about extraction reliability. Additionally, optimizing for real-time processing will open new applications in interactive document workflows and time-sensitive business processes.
Medium-term goals
Looking ahead to the next two to three years, the focus will shift toward specialized applications and ecosystem development. Industry-specific fine-tuning for sectors like healthcare, legal, and finance will unlock tremendous value by adapting models to domain-specific document types and terminology. The development of standardized APIs and workflow automation tools will facilitate broader adoption by making integration simpler for organizations without deep ML expertise.
Human-in-the-loop refinement systems will combine the efficiency of automated extraction with human expertise for critical validation, creating hybrid workflows that maximize both accuracy and efficiency. Cross-lingual document understanding capabilities will enable global organizations to process documents in multiple languages without separate models or translation steps.
Long-term vision
The ultimate vision for VLM based document processing extends far beyond current capabilities. Autonomous document processing systems with self-improvement capabilities will continuously learn from new document variations, reducing the need for manual intervention over time. Eventually, these systems will handle document understanding as naturally as humans do, adapting to new formats, languages, and content types without explicit retraining. Multimodal integration will expand beyond text and images to include audio annotations, embedded videos, and mixed media documents, creating truly comprehensive document understanding systems.
Advanced cognitive reasoning about document content will enable systems to not just extract information but understand implications, identify inconsistencies, and make intelligent decisions based on document content. Finally, robust compliance and validation frameworks will ensure these powerful systems operate within legal and regulatory boundaries while maintaining audit trails and explainability.
Implementation Strategy and Best Practices
Successful VLM deployment requires strategic planning across technical, operational, and organizational dimensions:
Model Selection Framework
Organizations should select VLM models based on their specific requirements across four key dimensions: accuracy needs, resource constraints, processing volume, and document complexity. For proof-of-concept implementations, DONUT provides an accessible entry point with minimal infrastructure requirements. Production environments processing standard business documents benefit from DocOwl2's balanced approach, while organizations requiring maximum accuracy on complex documents should consider Llama 3.2 Vision despite its higher resource requirements.
Deployment Considerations
Successful VLM deployment requires careful attention to infrastructure planning, data security, and integration requirements. GPU memory allocation, batch processing optimization, and failover mechanisms ensure reliable operation at scale. For regulated industries, on-premise deployment becomes essential, requiring careful consideration of model hosting, data flow, and audit trail maintenance.
Performance Optimization
Organizations can optimize VLM performance through strategic preprocessing, prompt engineering, and post-processing validation. Document quality normalization, strategic batching, and confidence threshold tuning maximize both accuracy and throughput while maintaining acceptable processing times.
Real World Impact and Case Studies
Production deployments across multiple industries demonstrate the practical effectiveness of VLM technology:
Financial Services Transformation – mPLUG-DocOwl2 (1)
A Fortune 500 financial services firm adopted mPLUG-DocOwl2 for enterprise-scale document intelligence, achieving an 83% reduction in document processing time and drastically reducing manual workload in loan application review and compliance documentation. The implementation demonstrates the transformative potential of VLM technology in high-stakes financial environments where accuracy and compliance are paramount.
Healthcare Compliance and Efficiency using VLM Run (2)
Valerie Health, a rapidly growing healthcare technology company, faced scale-blocking inefficiencies in processing diverse patient paperwork, insurance forms, and handwritten intake documents using legacy OCR and LLM combinations. The company's transition to VLM Run's vision-language API unified all document types: scans, faxes, handwritten forms, into accurate, structured, EMR-ready data with immediate HIPAA-compliant automation.
The unified API solution eliminated manual verification requirements, reduced infrastructure complexity, and enabled direct mapping of extracted fields to Electronic Medical Records with high confidence and enterprise compliance. This transformation saved thousands of processing hours while enabling rapid organizational scaling, demonstrating how VLMs can remove operational bottlenecks that constrain healthcare technology growth.
Manufacturing Invoice Processing using Llama 3.2 Vision (3)
A detailed implementation of fine-tuned Llama 3.2 Vision for manufacturing invoice processing reveals significant improvements in accuracy and workflow efficiency. Following fine-tuning on domain-specific invoice datasets, the system achieved marked improvements in extracting line-item details, monetary amounts, and handwritten totals from scanned invoices.
Business outcome analysis showed substantial improvements in processing accuracy, with error rates on critical financial fields dropping significantly after implementation. The model demonstrated particular strength in reading handwritten totals and understanding table structures where amounts and quantities maintain semantic relationships, enabling automated validation workflows that previously required manual oversight.
Conclusion and Strategic Implications
VLM based information extraction represents more than just a technical advancement. It's a fundamental reimagining of how machines understand documents. Our experiments clearly demonstrate that this technology has reached a level of maturity suitable for production deployment. With accuracies ranging from 42% to 67%, these models are production-ready for many use cases, offering viable alternatives to traditional OCR pipelines for organizations willing to embrace innovation.
The practicality of this approach cannot be overstated. While resource requirements are higher than traditional OCR, they remain manageable with modern infrastructure, and the rapid advancement in hardware efficiency continues to lower the barrier to entry. More importantly, by preserving visual context and understanding documents holistically, AI models capture nuances that traditional pipelines miss, leading to more accurate and meaningful information extraction.
The inclusion of DONUT in our analysis particularly demonstrates that the VLM paradigm shift is accessible to all organizations. Even with modest resources (4GB GPU) and baseline accuracy (52%), DONUT outperforms traditional OCR on complex documents while eliminating pipeline complexity. This proves that organizations don't need cutting-edge infrastructure to begin benefiting from VLM based information extraction.
This technology represents the future of document processing. As models improve and hardware becomes more powerful, this approach will inevitably become the standard across industries. The shift from OCR-based pipelines to direct visual understanding mirrors how humans actually process documents. We don't read character by character; we understand visually, contextually, and semantically all at once. Generative AI finally brings this human-like understanding to automated systems, closing the gap between human and machine document comprehension.
For organizations dealing with complex documents, mixed content types, or quality variations, the time to explore VLM-based extraction is now. The technology has matured sufficiently for production use, the benefits are clear and measurable, and early adopters will gain a significant competitive advantage in efficiency, accuracy, and capability. Whether starting with DONUT's lightweight approach or investing in Llama 3.2 Vision's superior accuracy, the question isn't whether to adopt this technology, but how quickly you can leverage it to transform your document processing workflows and unlock new possibilities for automation and insight generation.
This analysis is based on extensive testing with production document types using state-of-the-art Vision-Language Models. All metrics represent real experimental results from our research lab.
This whitepaper is written by Manish Jain, VP and Global Head of AI Architecture and Jyotiranjan Panda, Director - GenAI Solution Architect.
Most recent

Intelligent Context Framework: How enterprises turn decision context into institutional memory

AI vision-language models hit 96% accuracy on complex forms
